Als front-end ontwikkelaars denken we vaak na over wat onze code doet. Maar steeds vaker is waar die code draait minstens zo belangrijk. Serverless en edge computing geven ons nieuwe mogelijkheden om logica dichter bij de gebruiker te plaatsen. De juiste plek kiezen is daarbij lang niet altijd vanzelfsprekend.
Moet je content personaliseren aan de edge? Kun je alles in serverless functions draaien? Wanneer is een eenvoudige CDN voldoende? En wanneer heb je nog steeds een ouderwetse server nodig?
In deze blog leg ik uit hoe je bepaalt waar verschillende onderdelen van je applicatie moeten draaien. Ik laat zien hoe performance, schaalbaarheid en vendor lock-in invloed hebben op die keuze. Ook deel ik hoe we bij De Voorhoede klanten helpen om features te koppelen aan infrastructuur. En hoe je veelgemaakte fouten voorkomt bij het toevoegen van moderne tooling aan bestaande systemen.
Je kunt geen supercomputer in ieders broekzak stoppen
Ik ben dol op moderne technologie. Bij De Voorhoede pionieren we er graag mee.
Maar in alles wat we bouwen, zetten we de gebruiker voorop. En onze gebruikers? Die geven niets om welke technologie we kiezen of waar onze code draait. Ze willen gewoon een snelle, soepele en persoonlijke ervaring.
Het is verleidelijk om te denken dat code die dichter bij de gebruiker draait altijd sneller voelt. In veel gevallen klopt dat.
Minder latency - de tijd tussen interactie, code-uitvoering en UI-update - maakt een groot verschil.
Maar performance draait niet alleen om afstand. Het draait ook om rekenkracht. Wat het apparaat kan doen zodra het verzoek aankomt, bepaalt minstens zoveel.
Aan de client-kant hebben we geen controle over het apparaat van de gebruiker. Het kan een gloednieuwe iPhone zijn, of een zes jaar oude Android met tien tabbladen open.
Aan de serverkant hebben we die controle wel. We kunnen machines kiezen met meer CPU, geheugen of zelfs GPU-acceleratie.
De ideale situatie is lage latency én hoge capaciteit. Dat klinkt geweldig, maar is zelden realistisch.
Overal krachtige servers neerzetten is duur en lastig te schalen. En voor de meeste toepassingen is het simpelweg overkill. Je hebt geen supercomputer aan de edge nodig om iemands naam te tonen.
Wanneer we een applicatie ontwerpen, balanceren we voortdurend tussen latency en capaciteit.
Er bestaat geen universele oplossing. Het hangt af van wat elke feature nodig heeft.
Laten we de opties bekijken en zien waar ze goed (of minder goed) in zijn.
Gecentraliseerde servers: alles op één plek
Voordat we edge runtimes, serverless functies en wereldwijde CDNs hadden, draaiden de meeste webapplicaties op één centrale server. Veel doen dat nog steeds.
Een centrale server bundelt alles op één plek: compute, file storage, databaseverbindingen, templates en assets. Het is makkelijk te begrijpen en eenvoudig te beheren. Toen Node.js opkwam, werd de server ook onderdeel van ons domein bij De Voorhoede.
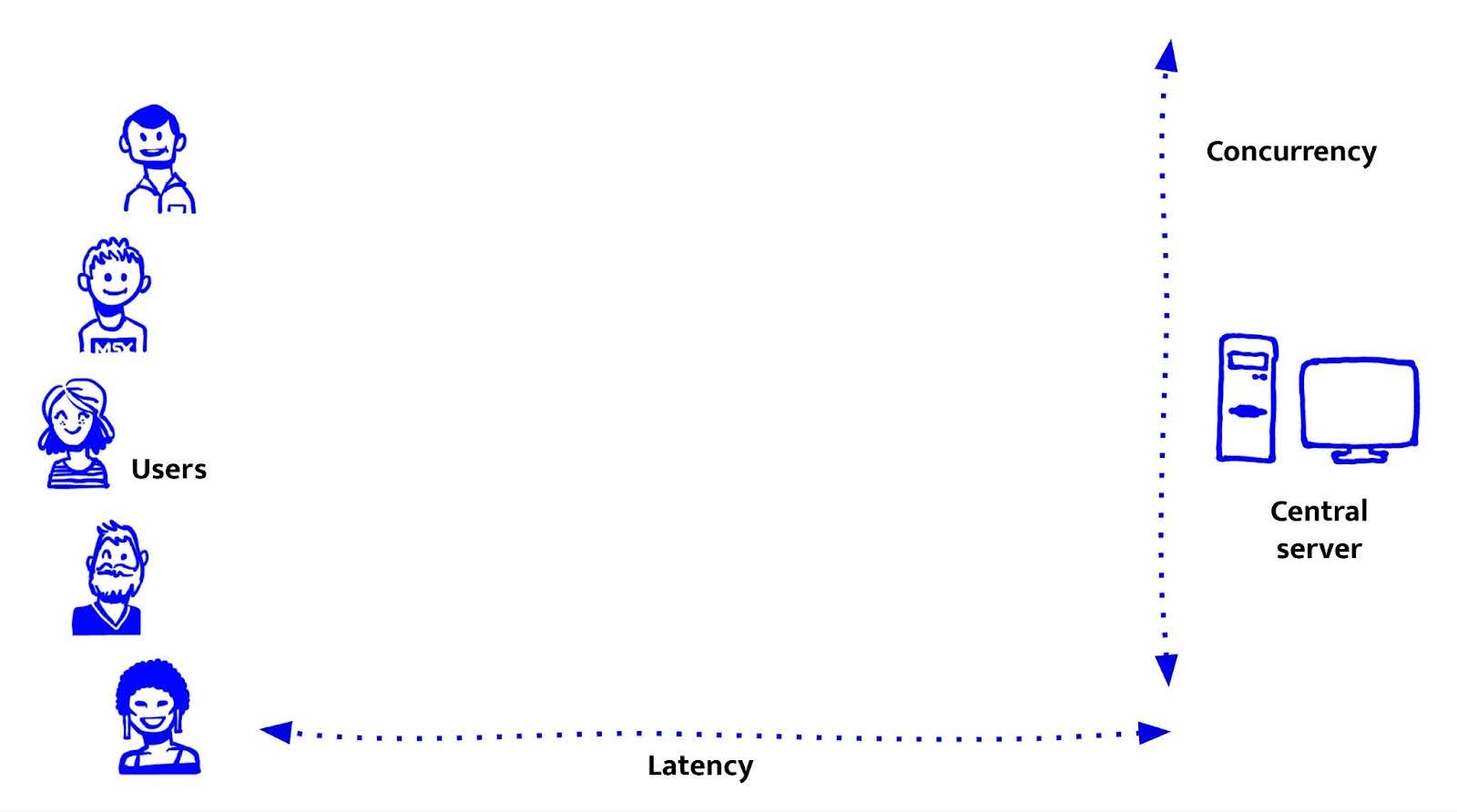
Tegenwoordig draaien centrale servers vaak in containers zoals Docker of Kubernetes. Deze tools maken het makkelijker om consistente omgevingen te deployen, workloads te schalen en tussen cloudproviders te wisselen. Toch blijft de architectuur grotendeels hetzelfde. Gebruikersverzoeken gaan naar één centrale locatie waar alles gebeurt.
Wanneer werkt dit model goed?
- Je gebruikers zitten geografisch dicht bij de server, bijvoorbeeld een Nederlandse organisatie met Nederlandse gebruikers.
- Je verkeer is voorspelbaar en goed te dimensioneren.
- Je wilt volledige controle over runtime en omgeving.
- Je applicatie heeft zware compute-taken of afhankelijkheden die niet goed werken in gedistribueerde omgevingen.
Wat zijn de nadelen?
- Latency: gebruikers verder weg merken vertraging, hoe goed je code ook is.
Schaalbaarheid: een enkele server heeft beperkte capaciteit. Piekverkeer vraagt over-provisioning of complexe orchestratie.
Beperkingen in flexibiliteit: alles draait op dezelfde plek. Zodra je functies verspreidt, ontstaat snel complexiteit.
En natuurlijk slaan we hier een groot onderwerp over: databases. Dat is een wereld op zich. Voor nu is het genoeg om te zeggen dat centrale servers vaak dicht bij hun database staan, en dat is niet zonder reden. Ze profiteren van lage latency, stabiele verbindingen en voorspelbare prestaties. Die nabijheid heeft ook een nadeel: het bindt je infrastructuur aan een fysieke locatie.
Kort samengevat geeft een centrale server je veel controle, kracht en eenvoud. Maar dat werkt alleen als de behoeften van je applicatie, je gebruikers en je verkeerspatronen allemaal rond dat ene punt samenkomen. Laten we nu kijken wat er gebeurt wanneer we onderdelen van het systeem gaan verdelen. We beginnen bij de eerste stap in die richting: CDNs.
CDNs, de eerste stap naar de edge: statische bestanden dichter bij de gebruiker
CDNs waren de eerste grote stap om het web dichter bij de gebruiker te brengen, al ging het toen alleen nog om statische bestanden. Ze verlagen de latency en nemen werk uit handen van je origin servers. Maar ze zijn ook beperkt, omdat ze geen logica kunnen uitvoeren of data kunnen ophalen. Begrijpen waar CDNs sterk in zijn en waar niet, is cruciaal om te beslissen waar front-end features moeten draaien.
Wat CDNs goed doen, is eenvoudig. Ze serveren statische bestanden, HTML, CSS, JavaScript en afbeeldingen, vanaf servers die fysiek dichter bij de gebruiker staan. Dat vermindert latency en bandbreedtekosten en maakt het eenvoudig om wereldwijd te schalen zonder extra infrastructuur op te zetten.
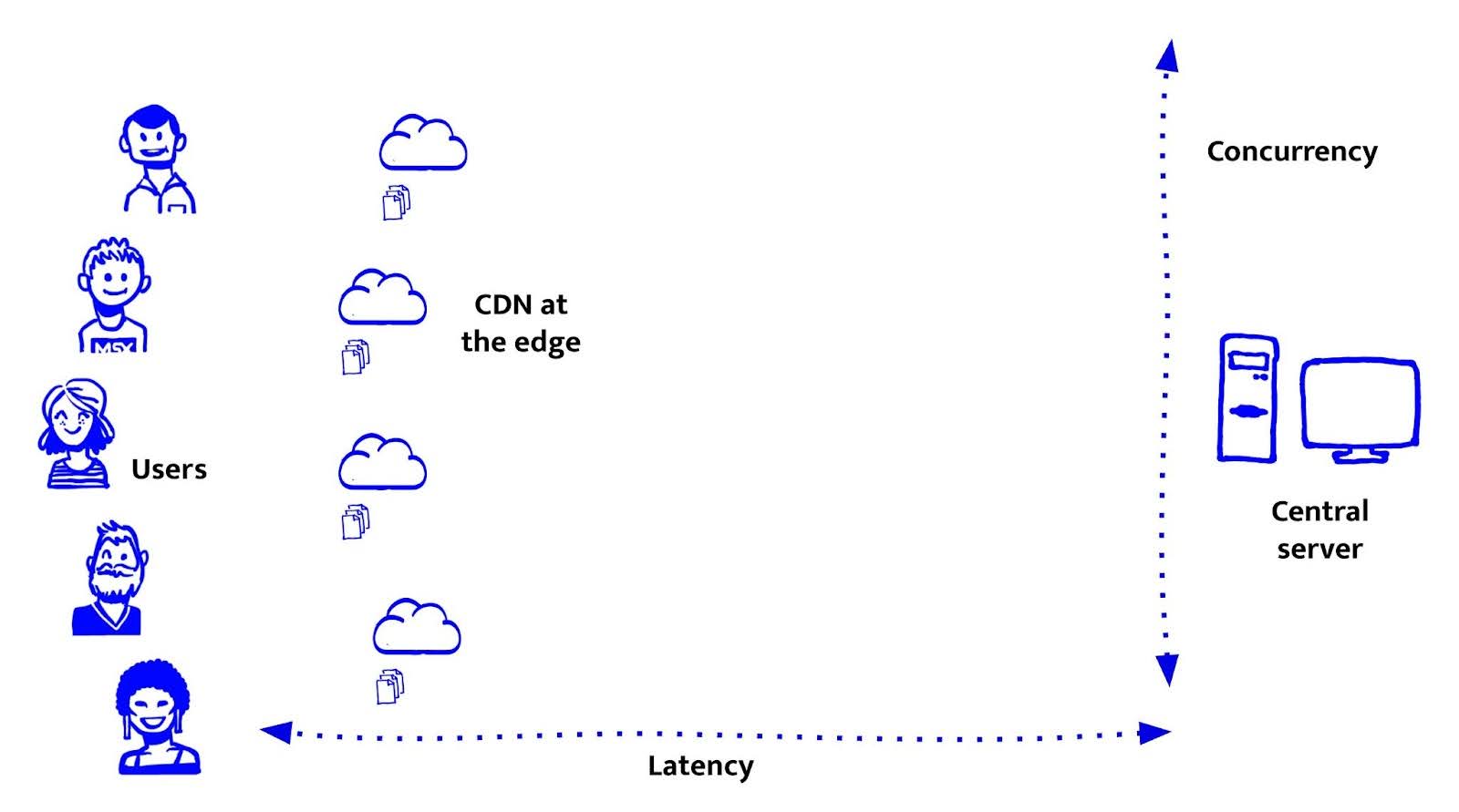
Voor ons bij De Voorhoede werden CDNs echt interessant met de opkomst van de JAMstack. Vooraf gerenderde HTML, gedeployed naar een CDN, maakte websites razendsnel en goedkoop om te hosten. Dankjewel Netlify. Het maakte ook de weg vrij voor headless architecturen, waarbij de front-end losgekoppeld is van CMS’en, commerce-engines en back-end systemen. Dat gaf ons een enorm voordeel. We konden aan de front-end blijven doorontwikkelen zonder afhankelijk te zijn van back-end teams. Preview-omgevingen werden de norm. In plaats van één acceptatie- en één productieomgeving kregen we een nieuwe deploy bij elke pull request. Het was snel, eenvoudig en gaf veel vrijheid.
Maar CDNs hebben hun grenzen. Een CDN is in de kern een server-side cache. Dat is perfect voor performance, maar beperkt in flexibiliteit. Je hebt een doordachte invalidatiestrategie nodig, bijvoorbeeld op tijd (max-age, stale-while-revalidate), op tags of handmatig, en uiteindelijk is de cache gedeeld. Ze kunnen geen logica uitvoeren of per gebruiker renderen. Voor dynamische situaties, zoals ingelogde gebruikers, A/B-tests of gepersonaliseerde content, moet je terugvallen op client-side oplossingen of opnieuw contact maken met je origin server.
Dus hoe brengen we compute dichter bij de gebruiker?
Serverless functies - compute dichterbij
Serverless functies, zoals AWS Lambda of Google Cloud Functions, brengen rekenkracht dichter bij de gebruiker. Niet helemaal tot aan de edge, maar wel naar regionale servers (zoals eu-central-1 of us-west-2). Ze staan dus dichterbij dan centrale servers en zijn flexibeler dan CDNs.
Ze zijn eenvoudig te gebruiken. Je deployt een functie, en die draait alleen wanneer nodig, of dat nu één keer is of een miljoen keer. Ze schalen automatisch, je betaalt niet voor stilstand en ze zijn ideaal voor lichte API-logica of CMS-integraties.
De meeste providers ondersteunen meerdere talen, waaronder JavaScript (Node.js). Dat maakte serverless voor ons bij De Voorhoede een logische stap. We konden in dezelfde taal blijven werken, back-end logica schrijven en deze naast de front-end deployen.
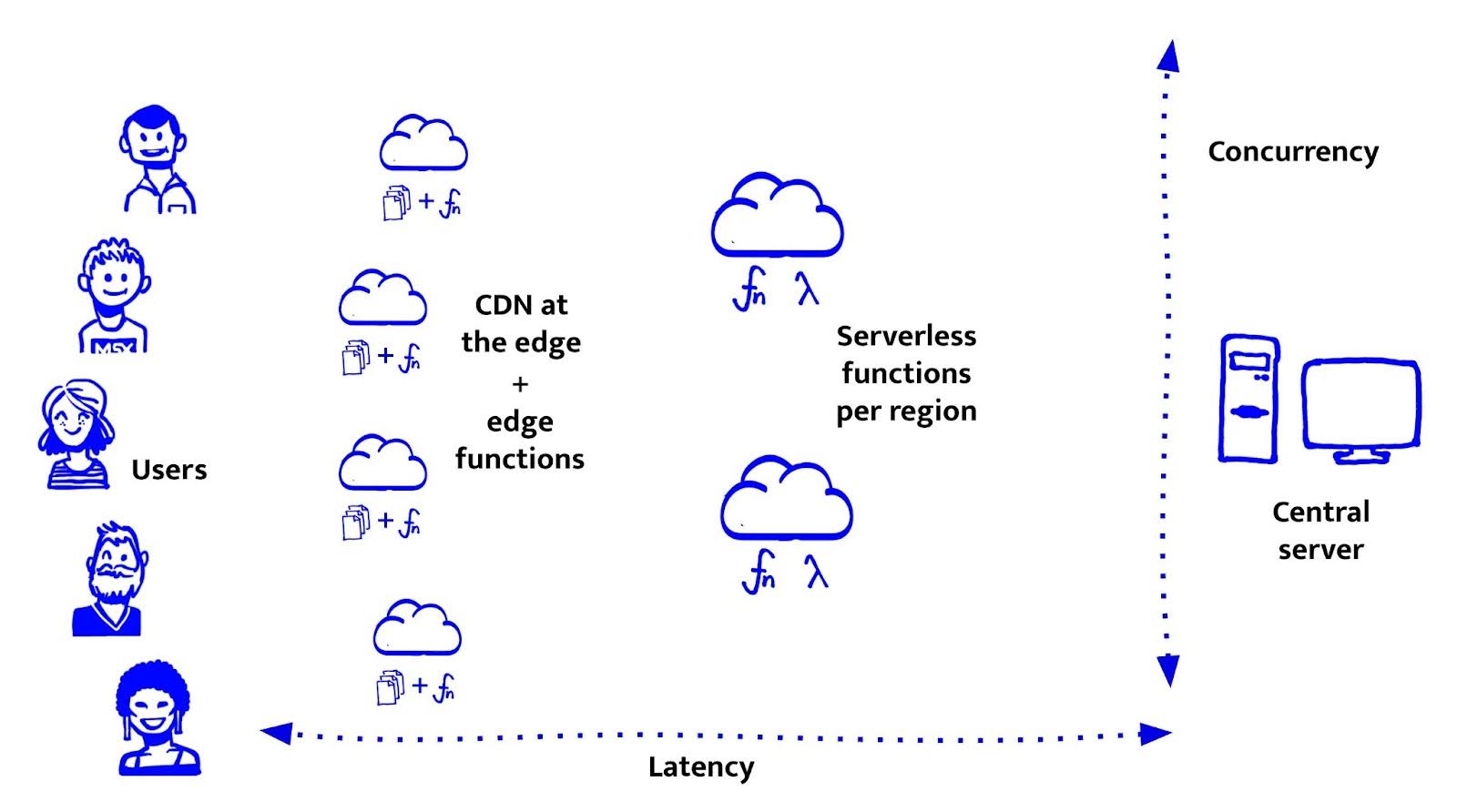
Maar serverless heeft ook nadelen:
- Stateless by design: elke functieaanroep start volledig opnieuw. Er is geen in-memory state en geen persistente verbindingen. Dat is prima voor lichte logica, maar wordt problematisch naarmate de applicatie groeit.
Cold starts: functies die een tijd niet zijn gebruikt, reageren trager. De opstarttijd kan variëren van enkele honderden milliseconden tot meerdere seconden, afhankelijk van het platform en de omvang van je code.
Niet alle packages werken goed: Node.js wordt ondersteund, maar sommige libraries met native dependencies of file system access functioneren slecht. Grote packages vertragen je functies merkbaar. Probeer Prisma met GraphQL en je merkt het meteen.
Platformspecifieke APIs: elke provider heeft zijn eigen manier om requests en responses te verwerken. Abstracties zoals het Serverless Framework kunnen helpen, maar voegen extra complexiteit en afhankelijkheid van de leverancier toe.
Serverless is een sterke stap richting modulaire, schaalbare infrastructuur. Maar als we nog snellere reactietijden willen en logica die draait vlak bij de gebruiker, dan is er nog een stap dichterbij: edge functions.
Edge functies - compute aan je voordeur
Met edge functies kunnen we dynamische logica draaien zo dicht bij de gebruiker als maar mogelijk is, zonder op hun eigen apparaat te draaien. Deze functies voeren code uit op dezelfde plekken waar onze statische bestanden al staan, de wereldwijde edge-locaties. Ze zijn ideaal voor lichte, latency-gevoelige taken zoals authenticatie, A/B-tests, rewrites en eenvoudige API-integraties.
In tegenstelling tot serverless functies draaien edge functies niet in containers of virtuele machines. Ze gebruiken isolates, lichte, sandboxed omgevingen die zijn ontworpen voor snelheid en schaal. Ze bieden extreem lage latency en vrijwel geen cold starts, maar hebben strikte limieten op resources. Ook ontbreken veel Node.js-functionaliteiten waar populaire pakketten van afhankelijk zijn.

Bekende runtimes zijn Cloudflare Workers, Deno Deploy en in mindere mate Bun. Zoals bij serverless heeft elke runtime zijn eigen API’s en eigenaardigheden. Dat maakt overdraagbaarheid van code lastig. Gelukkig werkt de WinterCG-groep aan de standaardisatie van web-API’s over verschillende runtimes. Daardoor kunnen we straks web-native JavaScript schrijven dat overal draait. De UnJS community werkt ondertussen aan kleine, runtime-onafhankelijke utilities zoals unenv, h3 en unstorage. Deze modules zijn ontworpen om “gewoon te werken”, ongeacht de omgeving.
Frameworks spelen een sleutelrol in het compleet maken van deze universele ontwikkelervaring. Astro, SvelteKit, Remix en Nuxt 3+ bieden runtime-adapters die je app geschikt maken voor edge-platforms zonder codewijzigingen. Deze adapters compileren je app naar de gekozen runtime en abstraheren de platform details. Zo blijft de output klein en performant. De opvallende uitzondering is Next.js, dat ondanks de open source licentie sterk verbonden is met Vercel en moeilijk volledig elders te draaien is.

Dus, hoe dichtbij moet jouw code zijn?
Het antwoord is eenvoudig: zo dichtbij mogelijk, met precies genoeg kracht voor de taak.
In vastgoed geldt het gezegde: location, location, location. Dat geldt net zo goed voor applicatielogica. Hoe dichter je code bij de gebruiker staat, hoe sneller en responsiever de ervaring voelt. Maar die snelheid komt met afwegingen. Edge runtimes zijn snel maar beperkt. Serverless voegt flexibiliteit toe, maar kost tijd. Centrale servers bieden controle, maar alleen als je gebruikers die extra afstand kunnen accepteren.
Samenvattend:
|
Criteria |
Statische CDN |
Edge Function (e.g. Workers) |
Regionale Serverless |
Gecentraliseerde Server |
|---|---|---|---|---|
|
Latency (nabij gebruiker) |
✅ | ✅ |
⚠️ (regionaal) |
❌ |
|
Schaalbaarheid (auto-scaling & volume) |
✅ | ✅ | ✅ |
⚠️ (infra vereist) |
|
Dynamische logica |
❌ | ✅ | ✅ | ✅ |
|
Cold starts |
❌ |
✅ (nagenoeg nul) |
❌ (kan traag zijn) |
✅ |
|
Zware berekeningen |
❌ | ❌ | ✅ | ✅ |
|
Portabiliteit (geen vendor lock-in) |
✅ |
⚠️ (runtime-specifiek) |
⚠️ (platform-specifiek) |
✅ |
|
Beste voor |
Static sites, assets |
APIs, gepersonaliseerde UIs, A/B-tests, authenticatie |
APIs, lichte serverlogica |
Monoliths, legacy systemen |
Bij De Voorhoede beginnen we altijd met dezelfde vraag: Wat is de minst krachtige, dichtstbijzijnde optie die dit onderdeel aankan?
- Als iets statisch kan zijn, pre-renderen en cachen we het.
- Als het lichte logica nodig heeft, draaien we het aan de edge.
- Alleen wanneer er meer rekenkracht of persistente verbindingen nodig zijn, gebruiken we serverless of centrale servers.
De moderne front-end gaat niet alleen over wat je bouwt, maar ook over waar je het draait. Met de tools van vandaag kunnen we die keuze nauwkeuriger maken dan ooit.