Cache all the things, even your HTML.
This post was originally posted on the Performance Calendar 2016.
Have you heard about the latest and greatest Progressive Web Apps and Service Worker? Well, we did and we got quite enthusiastic about it as well. Some technologies don’t need to prove themselves before we try them in production. So without further ado, straight from the top of our backlog: HTML caching with service worker.
Our use case: Caching HTML
Our static site is already pretty fast. We minify and compress all our files. We deliver a functional page as soon as possible by inlining CSS and lazy loading render blocking assets on the first view. To make subsequent page views as fast as possible, we aggressively cache everything. Well, everything except our HTML…
To ensure you always get the latest content, the page’s HTML is requested from the server on every page visit. However accessing the network and getting the page from the server takes time:
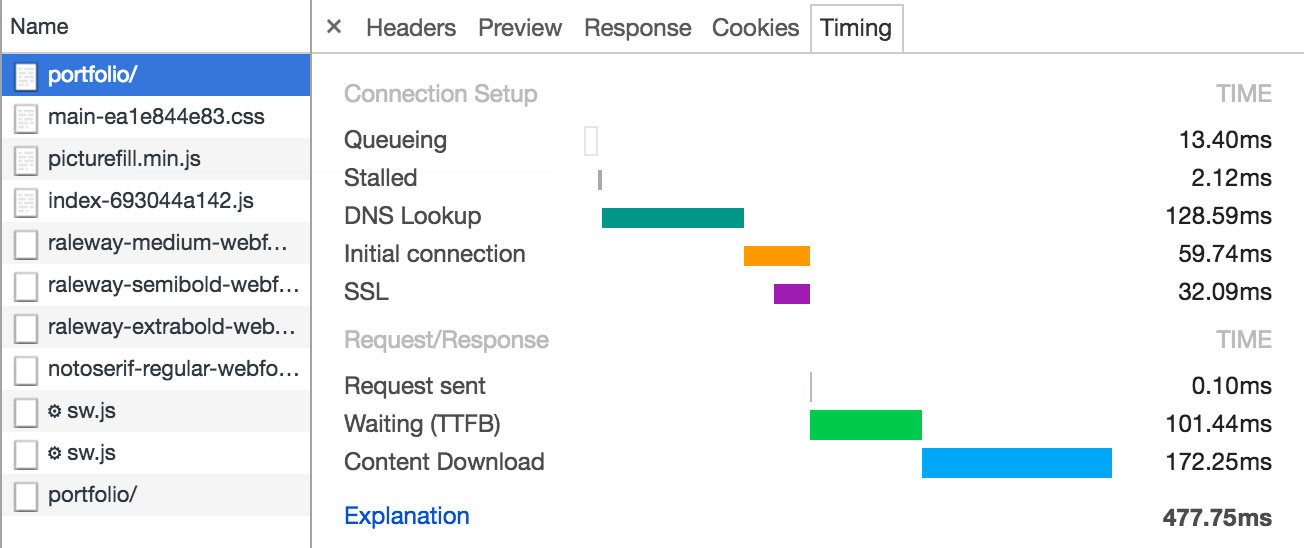
On Regular 3G (as Google Chrome defines it: 100ms delay, 750kb/s down, 250kb/s up) the HTML starts dripping in after 300ms. It takes almost half a second before the entire HTML page is downloaded. While this may seem pretty fast, half of that time is made up from waiting for the DNS lookup and initial server response, which is just waste. Besides that, we’re not trying to optimise our website for people on MacBooks with broadband internet; we’re going for the one that is on the road, with a crappy connection maybe even worse than 3G.
So that half a second load time for HTML described above makes sense for the first page visit, but not for repeat views. While we update our site quite often with new content, a lot stays the same. So we could speed up repeat views by caching the HTML:
Cache-Control: max-age=300Thanks for reading!… Hold on, this isn’t how we roll! We don’t just set the caching headers to 5 minutes, because:
- This would not guarantee up-to-date content, because during these 5 minutes we could have updated the HTML.
- We would needlessly invalidate cache many times without that being necessary. Since most of the time the HTML wouldn’t be updated during those 5 minutes.
And hey, since you’re still here, allow me to make this a bit more complicated and continue.
Introducing Service Workers
A Service Worker is a JavaScript file that sits between your webpage and the network. It is a type of web worker, so it runs separately from your page in its own thread. The nice thing about Service Workers is that they can intercept requests. Within the Service Worker file you have complete control over these intercepted requests. Meaning you can alter the request or response, send the request to the server or skip the server altogether and serve something from cache. We can leverage of this functionality for our HTML caching use case!
As a side note, we love the fact that Service Workers completely rely on progressive enhancement, which means we can enhance the user experience when Service Worker is supported. Without Service Worker support the page will simply be served by our server, which is fine, just a little slower.
An offline-first strategy
The best use of Service Worker we can think of in our case, is to let our website work offline, because you know what’s faster than the network? No network! So let’s try to use the network as little as possible. We aim at an offline-first strategy and let’s be clear about this: offline-first is not necessarily about making our website work offline. It is about not relying on the state of the network. Making the website work without internet connectivity is a bonus. Every user, regardless of the network status, will benefit from this approach. Whether you are offline, have a flaky 2G connection or are on high speed internet
Our approach looks like this:
- HTML files should be cached when they are requested.
- We serve HTML files from cache if they were cached before.
- If a requested HTML document has no cached version we “fall back” to the network.
- If we don’t have a cached version of the page and we don’t have network connectivity we serve an offline fallback page, sort of like a 404.
- We invalidate cache at some point to ensure always up-to-date content.
An HTML caching approach
We revision all our static files, except HTML, by appending a content hash to their filenames. Like <link rel=”stylesheet” href=”main-8008135.css”> Together with cache headers set to “never expire” we ensure these static files are only fetched when changed, and are otherwise served from the browser cache.
For HTML files though, we can’t change their filenames as this would result in “page not found” errors due to their URLs changing on every content change. We can, however, use the concept of content hashing in a different way for our HTML files.
HTML revisioning with content hashes
HTML pages can conditionally be stored and served from Cache Storagefrom within our Service Worker by making use of a hash table.
The hash table for our HTML pages looks something like this:
{
...
"/en/": "1db4c16510",
"/en/portfolio/": "2ab4423f75",
"/en/portfolio/a-brand-new-funda/": "7fce515b45",
"/en/portfolio/drop-and-fly/": "acafe43dac",
...
}A content hash (value) is mapped to the related URL (key) for each HTML page. The hash will be unique for every page, and consistent as well: the same input will generate the same output every time.
Let’s create this hash table or more specifically cache map by generating hashes of all our HTML pages:
const fs = require('fs');
const glob = require('glob');
const revHash = require('rev-hash');
const ext = 'index.html';
const htmlPages = glob.sync('**/' + ext);
const cacheMap = htmlPages.reduce((out, filePath) => {
const buffer = fs.readFileSync(filePath);
const url = '/' + filePath.substring(0, filePath.length - ext.length);
out[url] = revHash(buffer);
return out;
}, {});
module.exports = cacheMap;Cache HTML files
With the created cache map in place we include it in our Service Worker as a JavaScript object literal.
const HTML_MAPPING = {
...
"/en/": "1db4c16510",
"/en/portfolio/": "2ab4423f75",
"/en/portfolio/a-brand-new-funda/": "7fce515b45",
"/en/portfolio/drop-and-fly/": "acafe43dac",
...When an HTML file is requested we want to save it to Cache Storage, referenced by it’s unique hash. Every request passes the Service Worker and will fire a fetch event. This is the moment we can actually store it in Cache Storage. We listen to the fetch event:
self.addEventListener('fetch', event => {
const request = event.request;
if (isHtmlGetRequest(request)) {
event.respondWith(
getHtmlFile(request)
.catch(() => getFallbackPage(request))
)
}
});Since we are only interested in GET requests for HTML pages, we ignore the rest. After intercepting the HTML GET request we are, from within our getHtmlFile function, going to try to respond with an HTML file, be it from cache or the server. If both are unavailable, we will show a fallback page that acknowledges the user is offline, and doesn’t have a cached page. Our getHtmlFile function looks something like this:
function getHtmlFile(request) {
const cacheName = HTML_MAPPING[request.url];
return caches.open(cacheName)
.then(cache => cache.match(request.url))
.then(response => response ? response : fetchAndCache(request, cacheName));
}Based on the request url we find the HTML hash in our HTML_MAPPING, which acts as our unique cache key. We look in the Cache Storage and see if we get a response based on this key. If we find one, we know we have a cached version of our page. If there is no response we fetch it from the server and save in to the Cache Storage from within the fetchAndCachefunction:
function fetchAndCache(request, cacheName) {
return fetch(request)
.then(response => {
return caches.open(cacheName)
.then(cache => cache.put(request, response.clone()))
.then(() => response);
})
}
In the snippet above we use the Fetch API to get the file from the server. When we get the response we create a new cache store named after the unique hash by calling caches.open. This will return a cache object in which we save the response by calling cache.put.
Cache invalidation
There is a saying in computer science:
- Phil Karlton
There are only two hard things in Computer Science: cache invalidation and naming things.
So let’s do cache invalidation.
While a user browses our website, HTML pages are being cached and served from cache when requested again. At some point in time the content will be updated and the cached version will be out-of-date. Our build script ensures the HTML cache map is updated with new content hashes. Because this new cache map is included in our Service Worker, the previously installed Service Worker will be updated as the spec states: When a Service Worker is not byte-by-byte identical to an earlier installed Service Worker the old one will be replaced by the new one.
The updated HTML cache map can help us identify out-of-date caches. The cache map only contains entries for the latest version of each HTML page. These are the entries we potentially want to store. In other words: these are our “expected caches”. We create an expected caches array from our HTML cache map which results in a list of entries like:
const EXPECTED_CACHES =
[ ..., "1db4c16510", "2ab4423f75", "7fce515b45", "acafe43dac" , ...]Let us walk through this:
- We get all cache storage entries by calling
caches.keys(), where each key contains the unique hash. - We filter out all cache entries that are not inside our
EXPECTED_CACHESarray. - We delete the cache storage entry for all of our outdated caches.
The result
Phew! Was that all worth it? Well let’s look at the image below:
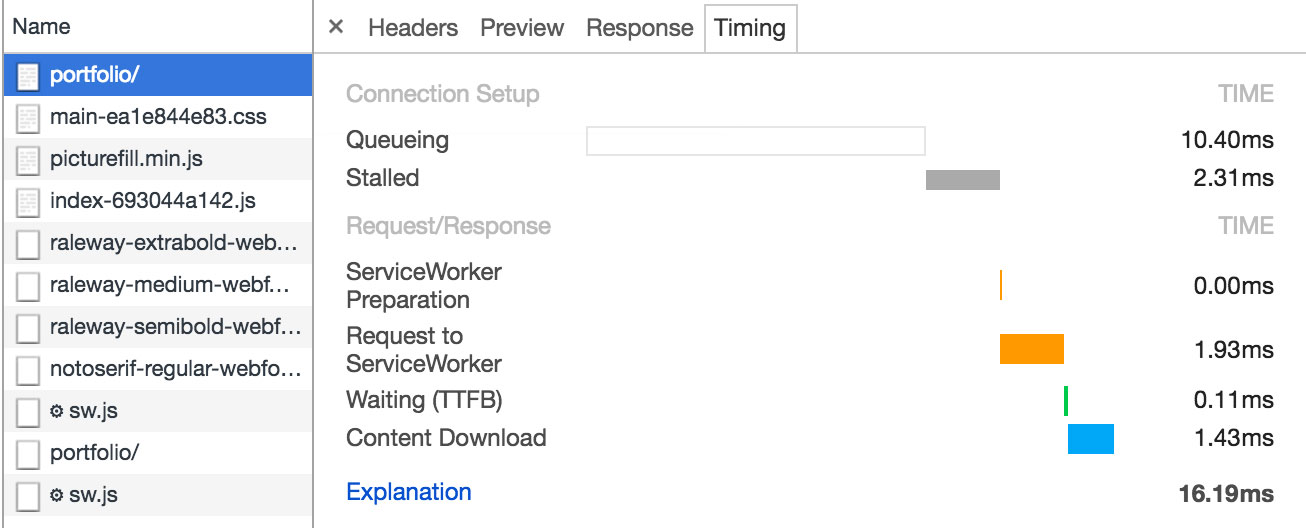
On a repeat visit the page is served from cache storage by the Service Worker, within a few milliseconds. That’s a lot faster than the half a second requesting the page on a regular 3G network. Actually our cached version will not suffer from network fluctuations and will even work offline as a bonus. Now that’s what we call supersonic HTML!