Experimenting with voice on the web using the Web Speech Synthesis and Recognition API
The Web Speech API is one of those web technologies that no one ever talks about or writes about. In this blog post, we are going to take a closer look at what the API is capable of, what its limitations and strengths are, and how web developers can utilize it to enhance the user’s browsing experience.
“The Web Speech API enables you to incorporate voice data into web apps. The Web Speech API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition)” — Mozilla Developer Network
Can the Web Speech API be used to interact with complex web forms? This is our research question for this blog post, and we are going to use both parts of the API to answer it. But let’s not get ahead of ourselves, let’s start by learning how the API actually works.
Making browsers talk with Speech Synthesis
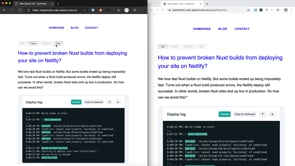
Note: Left: Microsoft Edge | Right: Google Chrome
Demo: https://experiment-web-speech.now.sh/pages/blog.html
Controlling the browser’s voice using Speech Utterance
We are going to use the Speech Synthesis API to read out one of our previous blog posts. The speechSynthesis interface is the service controller. This interface can be used to retrieve the available synthesis voices on the user’s device, play and pause the speech, and much more.
The SpeechSynthesisUtterance interface represents a speech request. It contains the text that the speechSynthesis service will read out, and it contains basic information like the voice’s pitch, volume, language, and rate.
const speechSynthesis = speechSynthesis;
const speechUtterance = new SpeechSynthesisUtterance();
function isPreferredVoice(voice) {
return ["Google US English", "Microsoft Jessa Online"].any(preferredVoice =>
voice.name.startsWith(preferredVoice)
);
}
function onVoiceChange() {
speechSynthesis.addEventListener("voiceschanged", () => {
const voices = speechSynthesis.getVoices();
speechUtterance.voice = voices.find(isPreferredVoice);
speechUtterance.lang = "en-US";
speechUtterance.volume = 1;
speechUtterance.pitch = 1;
speechUtterance.rate = 1;
});
}When a website is fully loaded, the speechSynthesis API will fetch all available voices asynchronously. Once done, it will fire a voiceschanged event letting us know that everything is ready to go. Utterances added to the queue before this event is fired will still work. They will, however, use the browser’s default voice with its default settings.
The getVoices() method will return every loaded voice. This list contains both native voices and browser-specific ones. Not every browser provides custom voice services, both Google Chrome and Microsoft Edge do. Generally speaking, these voices sound much better, but you are sacrificing privacy for quality. They also require an internet connection.
Warning: While using Google Chrome’s custom voice service, each utterance instance has a character limit of 200-300. If the utterance’s text changes, the limit is reset. It is unknown whether this is a limitation or a bug.
The function above sets up our SpeechSynthesisUtterance instance once the voiceschanged event is fired. Using the Array.find() method I select my voice of choice, gracefully falling back to the browser’s default.
Reading content outloud with .speak()
function onPlay() {
playButton.addEventListener("click", () => {
speechSynthesis.cancel();
speechUtterance.text = getElementText(blogPost);
speechSynthesis.speak(speechUtterance);
});
function getElementText(element) {
return Array.from(element.children)
.map(item => item.textContent.trim())
.map(addPunctuation)
.join("");
}
function addPunctuation(text) {
const hasPunctuation = /[.!?]$/.test(text);
return hasPunctuation ? text : text + ". ";
}
}Everything is ready and configured, now we need some content which speechSynthesis can read aloud. The function getElementText loops through our blog post, concatenating the content of each element to a single string.
You may have noticed the addPunctuation function. This function makes sure that the speechSynthesis interface adds a pause after each sentence.
There is a rare Chrome bug that can freeze the speechSynthesis API throughout the entire browser window. Running the cancel() method before the speak() method will always unfreeze the API. Finally, we set the SpeechSynthesisUtterance text to the value of getElementText and bind everything to an event listener.
if (speechSynthesis && speechUtterance) {
onVoiceChange();
onPlay();
}Now, all we need to do is to check whether both interfaces are supported.
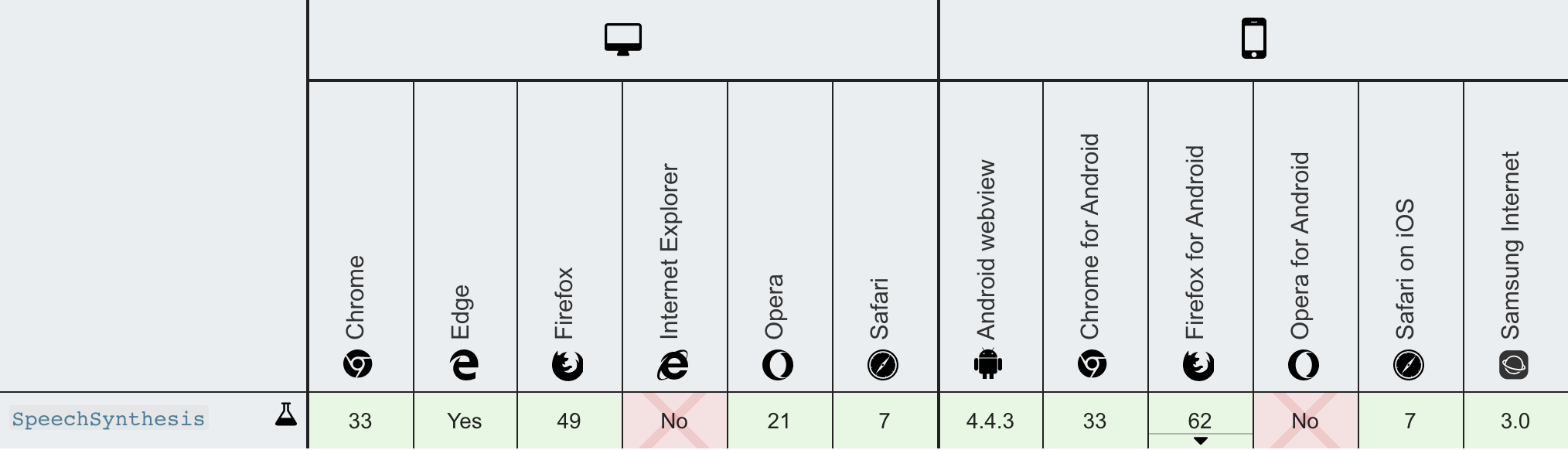
SpeechSynthesis is supported in all major browsers except IE
Listening to users with Speech Recognition
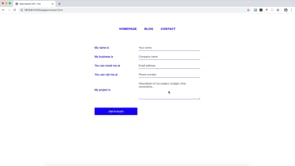
Note: This part of the experiment requires Google Chrome.
Demo: https://experiment-web-speech.now.sh/
Shouldn't it be awesome to navigate a website using voice commands? Yes, it should, so let’s build it! We can easily achieve this using SpeechRecognition. For this demo, we are going to create three voice commands, “search for…”, “go to …” and “navigate to …”. The last two being identical. The API will continuously listen for new commands and react accordingly to each one.
const SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
if (SpeechRecognition) {
const recognition = new SpeechRecognition();
recognition.lang = "en-US";
recognition.continuous = true;
recognition.interimResults = false;
}If the user's device supports the SpeechRecognition API, we configure it straight away. We want the API to keep listening for new commands after parsing the previous one. By setting continuous to true we achieve the desired result. For our use case, we do not want to receive interim results, we only need the final recognition; so we set interimResults to false. The lang property speaks for itself.
Executing voice commands
To track and manage all valid commands, we store them in an object called commands.
const commands = {
"search for": term => (searchInput.value = term),
"navigate to": destination => navigateTo(destination),
"go to": destination => navigateTo(destination)
};
function navigateTo(destination) {
const destinationLocations = {
home: "/",
homepage: "/",
contact: "/contact",
blog: "/blog"
};
const location = destinationLocations[destination];
if (location) {
window.location.href = location;
} else {
console.log(`Unknown destination: '${destination}'`);
}
}Each command has a callback function. The function receives a parameter containing the remainder of the recognized speech. This means that if the user says “navigate to contact”, the “navigate to” command will be fired, and its callback function will receive the string contact as the parameter.
function onSpeechRecognitionEvents() {
recognition.addEventListener("result", event => {
if (typeof event.results === "undefined") return;
const transcript = event.results[event.results.length - 1][0].transcript
.toLowerCase()
.trim();
for (let command in commands) {
if (transcript.indexOf(command) === 0) {
if (transcript[command.length] === undefined) {
commands[command]();
} else {
const param = transcript
.substring(command.length, transcript.length)
.trim();
commands[command](param);
}
}
}
});
}The SpeechRecognition's result event fires once the API has finished transcribing some user input. The event.result array keeps track of every returned result, which means the last array item is the latest recognized transcript.
We then need to loop through our commands object and check if the recognized transcript is something we are listening for. If it is, we check if the command received any parameter or not, in both cases, we call the commands' callback function.
if (SpeechRecognition) {
onSpeechRecognitionEvents();
recognition.start();
}We are now ready to initialize our event listeners and to call speechRecognition.start() to start listening for user commands.
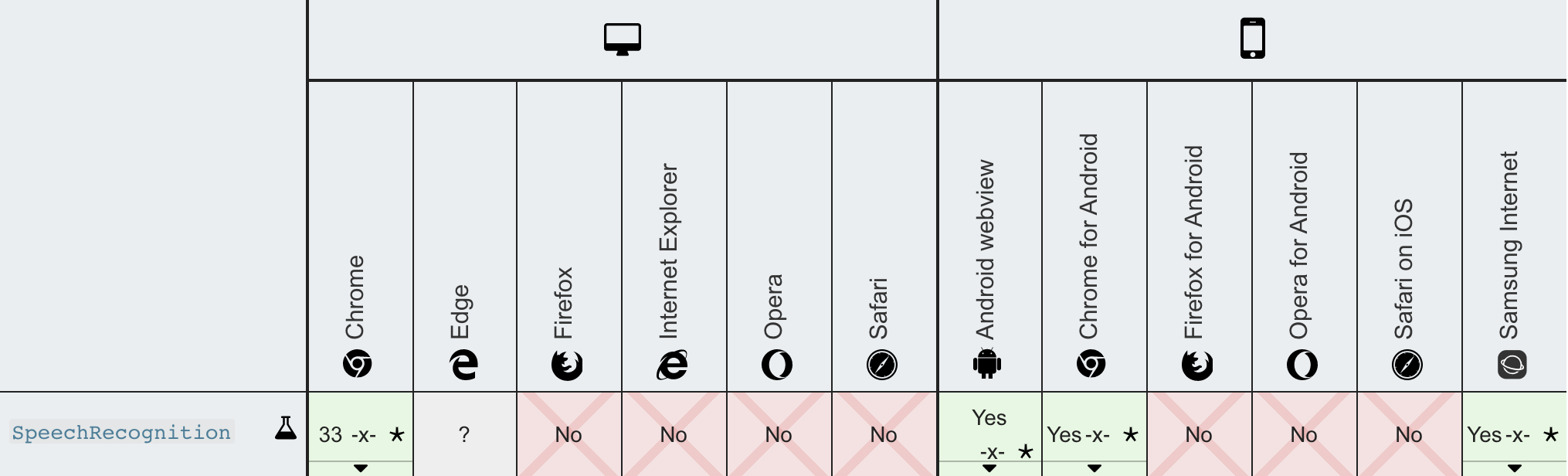
Putting Everything Together
Note: This part of the experiment requires Google Chrome.
Demo: https://experiment-web-speech.now.sh/pages/contact.html
For the final demo, I wanted to combine both interfaces to improve the user’s experience of filling out web forms. Once a user focuses on an input field, textarea or button, its associated label is going to be read aloud using speechSynthesis. The user can then fill in the form using his voice.
I have extracted most of the required code from the previous two demos, so I won’t explain everything in detail. I will, however, explain any new concept or workaround if applicable.
function speak(message) {
if (speechSynthesis.speaking) {
speechSynthesis.cancel();
}
speechUtterance.text = message;
speechSynthesis.speak(speechUtterance);
}Every time a form element is focused, the function above is called. The message parameter equals the associated label. speechSynthesis.cancel(); makes sure to replace the current utterance in place of adding a new one to the queue. This is important in case the user is skipping input fields using the tab key.
function onSpeechUtteranceEvents() {
speechUtterance.addEventListener("end", () => {
speechRecognition.abort();
speechRecognition.start();
});
}The SpeechRecognition and speechSynthesis interfaces do not work well together, at least, not if they are activated simultaneously. To prevent strange bugs and unwanted results, we make sure to only start transcribing the user’s input after the speechSynthesis interface is done speaking.
Conclusion
The Web Speech API is powerful and somewhat underused. However, there are a few annoying bugs and the SpeechRecognition interface is poorly supported. speechSynthesis works surprisingly well once you iron out all of its quirks and issues. Some browsers provide custom voices, and these voices sound better than the native ones. Their quality does vary a lot from browser to browser; Microsoft Edge’s sounds much more natural compared to Google Chrome’s, for example.
SpeechRecognition works fine for short sentences; results tend to get inconsistent with longer paragraphs. SpeechRecognition is also quite bad at recognizing more complex character sequences like email addresses and phone numbers. Thus, I should say that the Web Speech API is not suited for interacting with web forms. Yet, it does have its use cases if you are creative enough.